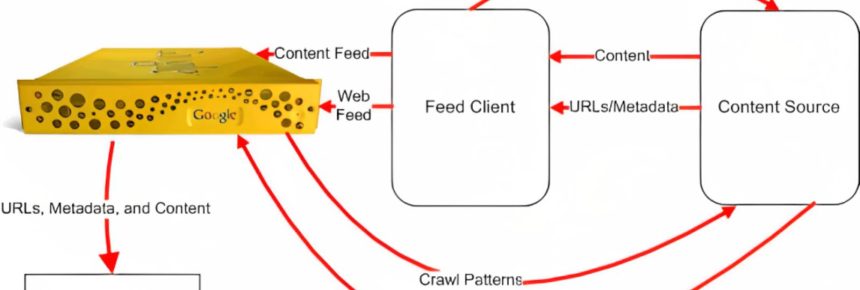
Arranging database crawling and serving includes a series of steps that are dependent on the particular database management system being utilized. In any case, there are a few common steps that are common to most systems. Here are the steps you’ll take after to arrange database crawling and serving:
Identify the information sources: The primary step is to identify the data sources you need to crawl. This can be databases, web applications, APIs, or record systems.
Choose a crawling device: Once you have got recognized the information sources, you wish to select a crawling tool that can interface to the data sources and extricate the information. A few well known crawling devices incorporate Apache Nutch, Scrapy, and Heritrix.
Configure the crawling device: After selecting a crawling device, you would like to design it to put through to the information sources and extricate the information. This includes indicating the information source URL, verification qualifications, and other relevant parameters.
Schedule the crawl: Once the slithering instrument is configured, you wish to plan the crawl to run at normal interims. This guarantees that the information is always up-to-date.
Store the data: As the crawling instrument extricates information from the information sources, you would like to store it in a database. This may well be a social database like MySQL or PostgreSQL, or a NoSQL database like MongoDB or Cassandra.
Index the information: Once the data is put away within the database, you would like to list it so that it can be looked and recovered productively. This involves making indexes on the important fields.
Serve the data: Finally, you wish to serve the information to the clients. This can be through a web interface or an API. You would like to guarantee that the information is served safely which as it were authorized clients can get to it.
Overall, arranging database crawling and serving could be a complex prepare that requires mastery in database administration, web slithering, and server organization. It is prescribed merely look for the assistance of a proficient on the off chance that you’re not commonplace with these advances.
Providing Database Data Source Information:
Giving database data source data is an essential step in interfacing to a database. This data incorporates the server title, port number, database title, username, and watchword.
Server name: The server name is the hostname or IP address of the machine that has the database. It might be a nearby or inaccessible server.
Port number: The port number is the organize harbour utilized by the database server to acknowledge approaching associations. The default port number for numerous databases is 3306 for MySQL and 5432 for PostgreSQL.
Database name: The database name is the name of the particular database you need to associate to. A database server may have multiple databases, and you wish to indicate which one you need to access.
Username: The username is the title of the client account that has get to to the database. You wish to supply the username and password to authenticate the connection.
Password: The watchword is the mystery key that grants access to the database. You ought to guarantee that the password is secure and not shared with unauthorized users.
Depending on the database management system being utilized, there may be extra parameters to supply. For case, for Microsoft SQL Server, you will have to be indicate the occurrence title and database driver. For Prophet, you will ought to give the Prophet Benefit Title or SID.Overall, giving precise and total database information source data is basic for building up a fruitful association to the database. It is vital to confirm that the data given is adjust some time recently endeavoring to put through to avoid any potential mistakes.
Crawl Queries:
Crawl questions are utilized to extricate information from website or web application by indicating the pages to be crawled and the information to be extricated. Here are a few cases of crawl queries:
Extracting all item data from an e-commerce site: To extricate all product information from an e-commerce site, you’ll utilize a slither inquiry that indicates the pages where the item data is found, such as the item category pages or item detail pages. You may at that point extricate the item title, portrayal, cost, and other pertinent data from each page.
Scraping job listings from a work board: To extricate work postings from a work board, you may utilize a crawl inquiry that indicates the pages where the work postings are found, such as the look comes about pages or person work pages. You may at that point extricate the work title, company title, area, work description, and other significant data from each page.
Gathering news articles from a news site: To gather news articles from a news site, you’ll utilize a crawl inquiry that indicates the pages where the news articles are found, such as the homepage or person article pages. You’ll at that point extricate the article title, author, distribution date, substance, and other pertinent data from each page.
Collecting social media posts from a social media stage: To gather social media posts from a social media stage, you’ll utilize a crawl inquiry that indicates the pages where the posts are found, such as the client profile pages or look comes about pages. You may at that point extract the post content, client title, post date, and other important data from each page.Crawl questions can be customized to extricate particular information from websites or web applications. Be that as it may, it is critical to guarantee that the crawling handle is legitimate and moral, which it does not damage any terms of benefit or copyright laws.
Crawl and Serve Query Examples:
Sure, here are some examples of crawl and serve queries:
- E-commerce website:
- Crawl query: Extract all product information from the product category pages.
- Serve query: Retrieve product name, description, price, and other relevant information from the products table and present them in a table format
- Crawl query: Extract job listings from the search results pages.
- Serve query: Retrieve job title, company name, location, job description, and other relevant information from the jobs table and present them in a list format.
- Crawl query: Gather news articles from the homepage.
- Serve query: Retrieve article title, author, publication date, content, and other relevant information from the articles table and present them in a blog format.
- Crawl query: Collect social media posts from user profile pages.
- Serve query: Retrieve post text, user name, post date, and other relevant information from the posts table and present them in a feed format.
- Crawl query: Extract medical research studies from the research studies page.
- Serve query: Retrieve study title, authors, publication date, abstract, and other relevant information from the studies table and present them in a table format.







