
The internet is an sea of data, with endless websites, pages, and assets holding up to be found. Exploring this endless ocean of information physically may be a overwhelming assignment. That’s where web crawlers come into play. Web crawlers, moreover known as insects or bots, are mechanized devices that systematically navigate the net, ordering and collecting data from websites. In this web journal post, we’ll dive into the world of web crawlers, exploring their usefulness, benefits, and potential utilize cases for comprehensive information gathering.
How Web Crawlers Work
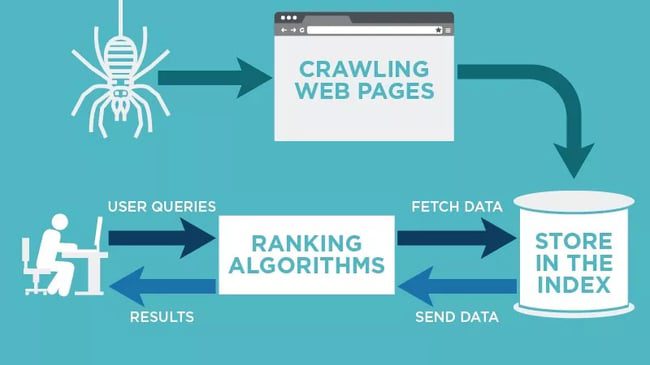
At their core, web crawlers are sophisticated programs designed to browse and retrieve information from web pages. They start by visiting a seed URL, from which they extract links to other pages. These links are then added to a queue, and the crawler continues its journey, visiting each page and extracting relevant data. The process continues recursively, allowing the crawler to explore vast portions of the web.
Types of Web Crawlers
There are different sorts of web crawlers custom fitted for different purposes. General-purpose crawlers, like those utilized by search engines, point to record as numerous pages as possible. Centered crawlers, on the other hand, target particular points or spaces, collecting information significant to a specific subject. Vertical crawlers specialize in gathering data from particular sorts of websites, such as news or e-commerce stages. Understanding the distinctive sorts of web crawlers permits you to select the foremost appropriate one for your information gathering needs.
Benefits of Web Crawlers for Data Gathering
Web crawlers offer numerous benefits when it comes to comprehensive data gathering:
- Adaptability: With robotization, web crawlers can handle a expansive volume of web pages in a generally brief time, making them perfect for collecting tremendous sums of data.
- Efficiency: Web crawlers can explore websites and extricate information at a much quicker pace than manual information collection, sparing time and exertion.
- Data Accuracy: By employing predefined rules and algorithms, web crawlers can ensure consistent and accurate data extraction, minimizing human errors.
- Data Aggregation: Web crawlers can gather data from multiple sources, consolidating information into a centralized repository for further analysis and processing.
Legal and Ethical Considerations
While web crawling provides immense benefits, it is essential to consider legal and ethical aspects. Some websites may have specific terms of service or robots.txt files that prohibit or limit web crawling. It is crucial to respect these guidelines and obtain permission when necessary. Additionally, web crawling should be performed responsibly, ensuring that privacy and copyright laws are upheld, and sensitive or personal data is handled with care.
Use Cases for Web Crawlers
Web crawlers have diverse applications across various industries:
- Search Engine Indexing: Search engines like Google and Bing rely on web crawlers to index web pages, making them searchable for users.
- Market Research: Web crawlers can collect data on competitors, pricing information, customer reviews, and industry trends, providing valuable insights for market research.
- Content Aggregation: Web crawlers can gather articles, blog posts, and news from different sources, creating curated content platforms or news aggregators.
- Sentiment Analysis: By crawling social media platforms and online forums, web crawlers can gather data on public opinion and sentiment about products, brands, or topics.
- Academic Research: Web crawlers can assist researchers in collecting data for studies, such as analyzing scientific papers, patents, or demographic information.
Tools and Frameworks for Web Crawling
Several tools and frameworks are available to facilitate web crawling, such as Scrapy, BeautifulSoup, and Selenium. These tools provide functionalities for crawling, data extraction, and handling complex web structures. Understanding the features and capabilities of these tools can empower you to build efficient and customized web crawlers.
Best Practices for Web Crawling
To ensure effective web crawling, consider the following best practices:
- Politeness: Respect website guidelines, including crawl rate limits and robots.txt instructions, to avoid overloading servers or infringing on website policies.
- Throttling: Implement throttling mechanisms to control the speed and frequency of requests, preventing excessive load on targeted websites.
- Data Quality Assurance: Validate and clean extracted data to ensure its accuracy, consistency, and relevancy.
- Error Handling: Implement error handling mechanisms to handle network errors, timeouts, or unexpected website behaviors.
- Regular Updates: Maintain and update your web crawler regularly to adapt to changes in website structures, policies, or security measures.
Conclusion
Web crawlers are powerful tools for comprehensive data gathering, enabling the exploration of the vast depths of the web. By automating the process of website traversal and data extraction, web crawlers offer scalability, efficiency, and accuracy. However, it is essential to navigate legal and ethical considerations, respecting website guidelines and privacy regulations. By leveraging web crawlers effectively and responsibly, businesses, researchers, and individuals can unlock a world of valuable information, driving informed decision-making and gaining a competitive edge in the digital landscape.







