In today’s data-driven world, accessing and extracting valuable data from the endless ocean of the web is vital for businesses, analysts, and people alike. Google Look, being the foremost widely used look engine, holds a wealth of information that can be harnessed for various purposes. In this comprehensive guide, we’ll explore the process of crawling data from Google Search, along with the easiest and most compelling methods to accomplish this task.
Understanding Web Crawling:
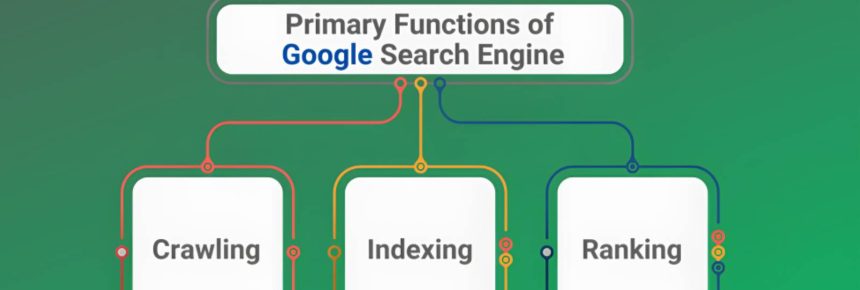
To start our journey, let’s begin with the concept of web slithering. Web slithering includes the robotized extraction of information from websites, empowering clients to gather data at scale. When it comes to Google Search, slithering information alludes to getting search results and extricating significant information from them.
Step-by-Step Direct to Slither Information from Google Search:
Define your Information Necessities: Begin by clearly characterizing the information you wish from Google Look. Are you trying to find particular catchphrases, site URLs, or other data? Having a clear objective will offer assistance to streamline the slithering process.
Choose the Correct Apparatuses: A few tools can assist in crawling information from Google Search. Some prevalent alternatives include Scrapy, BeautifulSoup, and Selenium.
Set up Your Development Environment: Install the chosen tool and set up the necessary conditions in your development environment. This typically includes installing Python, if required, and configuring the tool agreeing to the documentation.
Craft Your Crawler: Create a crawler utilizing the chosen instrument to explore through Google Look at the result pages. The crawler ought to mimic human-like behavior, counting, taking care of look questions, clicking on look comes about, and extracting information from the gone-by pages.
Implement Information Extraction: Characterize the information extraction rationale inside your crawler to parse the HTML structure of the look comes about and extricate the required data. This may include utilizing XPath or CSS selectors to find particular components on the page.
Handle Anti-Scraping Measures: Google utilizes anti-scraping measures to ensure its look motor. To maintain a strategic distance from discovery and potential IP blocking, actualize strategies like utilizing pivoting intermediaries, client operator turn, and including delays between requests.
Store and Analyze the Extricated Information: Once the crawler recovers the information, store it in an organized arrangement such as CSV, JSON, or a database. This empowers simple investigation and encourages handling of the extricated information.

The Least demanding Way to Creep Information from Google Search:
While the over steps diagram is a comprehensive approach, an elective alternative for information extraction from Google Look is to utilize pre-built scratching apparatuses and administrations. These devices frequently provide a user-friendly interface and watch out for specialized complexities, permitting non-technical clients to extract information easily. A few well known scratching instruments incorporate Octoparse, Import.io, and ParseHub.
Using such devices regularly includes contributing your look inquiries, indicating the information to extricate, and designing the scratching settings. The instrument at that point takes care of the slithering and information extraction preparation, giving you the required information in an organized format.
Best Phones for Creep Information from Google Search:
Respect Site Arrangements:
When slithering information from Google Look or any site, make beyond any doubt to audit and regard the website’s terms of benefit, robots.txt record, and any pertinent utilization approaches. Be careful of the volume and recurrence of your demands to maintain a strategic distance from over-burdening the website’s servers.
Use Intermediaries and Captcha Solvers:
To avoid IP blocking and bypass any captcha challenges, consider utilizing turning intermediaries and captcha understanding administrations. These apparatuses offer assistance to keep up secrecy and guarantee continuous crawling.
Monitor and Overhaul Your Crawler:
Frequently screen your crawler’s execution, counting its capacity to handle changes within the website’s structure or anti-scraping measures. Overhaul your crawler as required to guarantee persistent information extraction.
Follow Moral Rules:
Continuously utilize the extricated information capably and morally. Regard security rules, copyright laws, and any lawful confinements related with the information you collect. Get vital consents in case required.
Conclusion:
Crawling information from Google Look opens up a world of conceivable outcomes for getting important data. By taking after the comprehensive direct given, you’ll create your own crawler or utilize user-friendly scratching instruments to easily extricate information. Keep in mind to follow the best homes, respect website approaches, and utilize the extracted information capably. With the proper approach and apparatuses, you’ll saddle the control of Google Look and open a riches of bits of knowledge to back your commerce, inquire about, or individual endeavors.







